kohsweblog
0から始めるNode.jsパフォーマンスチューニング

近年の Node.js は API のサーバとしてはもちろん、Nuxt.js や Next.js といった SSR や BFF などフロントエンドのためのバックエンド言語としての人気が高まっています。
フロントエンドエンジニアがコンテキストスイッチ少なくバックエンドの整備ができることは非常に大きな利点です。
ですが、フロントエンド(ブラウザ側)とバックエンド(サーバ側)ではパフォーマンスチューニングで見るべき点が大きく違います。
しかし Node.js アプリケーションのパフォーマンスイシューの見つけ方などがまとまっている資料は少ないです。
そこで、本記事ではフロントエンドエンジニアが Node.js でパフォーマンスイシューを見つけ、改善するため自分が普段パフォーマンスチューニングを依頼されているときにみている基礎的なポイトをまとめていきます。
1. 計測ステップlink
Node.js のパフォーマンスチューニングは「性能をよりよくする」というよりは「コードの書き方によって落ちてしまったパフォーマンスを元に戻していく」というイメージになります。どのような API や書き方がパフォーマンスを劣化させているのかを知ることが一番重要です。
そこでまず最初のステップはパフォーマンスの計測です。
何はともあれ計測をしない限り、そのシステムのパフォーマンスが高いのか、もしくは劣化してしまっているのかを判断することはできません。どこがボトルネックなのかを調査するためにも、まずは現状の測定からです。
そのために最初は下記の準備から入ります。
- 本番と同等の挙動をする環境を作る
- パフォーマンス計測ツールを入れる
本番と同等の挙動をする環境を作るlink
ステージング環境などすでに自由にいじれる環境がある場合にはこのステップは飛ばすことがあります。
ここで重要なことは NODE_ENV=production で起動する環境を作ることです。
Node.js のモジュールは慣例的に NODE_ENV=production という環境変数が与えられた時に本番環境とみなしているものが多いです。
例えば express は production の時に static files や view contents をキャッシュする仕組みが入っていたり、出力されるログが少なくなったりします。
余談ですが express の本番環境のベストプラクティスドキュメントはとてもよくできていて参考になります。
他にも React の Server Side Rendering に利用する react-dom-server は NODE_ENV=production の時に読み込むファイルが本番用のファイルに切り替わります。
デバッグログや不要なロジックが削除されることにより、大幅にパフォーマンスが変わるので NODE_ENV=production を与えて起動することが本番環境で運用する上で必須条件となります。
具体的にこのステップでやることは、アプリケーションコードから process.env.NODE_ENV が含まれるコードの grep です。
実際のアプリケーションコードはデータベースの接続先や別環境の API の呼び出しなど、環境によって挙動を変えることが多いでしょう。
この環境の切り替えを process.env.NODE_ENV を利用してやっていると、パフォーマンステストで高負荷をかけたものが本番を向いてしまう危険性があります。
こういった環境ごとに変わる挙動を制御する変数はなるべく一箇所に集めるのがパフォーマンステストがしやすいアプリケーションです。デバッグログの出力を本番環境以外では行いたい、という時などに process.env.NODE_ENV を直接アプリケーションコードに if 文で埋め込んでしまうことも多いですが、できる限り避けたほうがよいと思います。
例えば自分はアプリケーションを作るときには config ファイルに env を判断するパラメータを作成し、アプリケーションコードでは必ずこのパラメータにアクセスすると決めて作成しています。
データベースの接続情報なども、環境変数を production にした場合にも開発環境のデータベースにつなげるようにするため、接続モジュールの中に書いてしまうのではなく、どこか一箇所の config ファイルの中に書いておくのがよいと思います。
// config.js
const production = process.env.NODE_ENV === 'production'
module.exports = {
production,
db: {
url: production ? 'mongodb://localhost:27017/prod' : 'mongodb://localhost:27017/dev'
}
}
パフォーマンス計測ツールを入れるlink
次のステップではパフォーマンスの計測に入ります。ここは各自使い慣れているツールを利用しましょう。 様々なツールがありますが、最近の自分は vegeta という計測ツールを利用することが多いです。
パラメータは毎回変わりますが、大体以下のようなコマンドでパフォーマンスを計測します。ログインが必要なページでは header に Cookie を渡して計測します。
$ echo "GET http://localhost" | vegeta attack -rate=30 -duration=10s -workers=10 -header 'Cookie: xxx' | vegeta report
duration で継続時間を指定して、rate で req/s を調整します。この辺は自分の感覚値ですが rate=30 くらいは最低でも食えることを目標にします。
もちろん食えるリクエスト数が増えれば増えるほどよいのですが、パフォーマンスチューニングのためにトリッキーなコードになったりするより、サーバを並列に並べてしまったほうが運用コストが低くなることもあるので、見極めが重要です。
結果の中で一番注目するべきは Latencies と Success です。
Requests [total, rate, throughput] 300, 30.09, 29.75
Duration [total, attack, wait] 10.084217496s, 9.969010607s, 115.206889ms
Latencies [mean, 50, 95, 99, max] 118.262733ms, 115.071858ms, 152.870202ms, 274.895501ms, 337.340772ms
Bytes In [total, mean] 5559600, 18532.00
Bytes Out [total, mean] 0, 0.00
Success [ratio] 100.00%
Status Codes [code:count] 200:300
Error Set:
Success はレスポンスがステータスコード 200 で返ってきた率で、ここは 100% を維持する必要があります。
たまに結果がすごくよくなった!と感動していると Success が 0% になっていて、全部エラー処理に入っていたから早かっただけということがあります。
Latencies は平均, 50%, 95%, 99%, 最大のレスポンスタイムが表示されています。ここはシステムによっても目標とする数字は変わりますが、自分は1秒以内を目安としてチューニングを行っていることが多いです。
2. パフォーマンス改善ステップlink
先のステップでパフォーマンスを計測する準備ができたので次はいよいよ改善に取り掛かります。
自分は重要度順にファイルディスクリプタ > cluster > アプリケーションコードの改善の順番で見ています。
パフォーマンスチューニングというとアプリケーションコードの改善にまず取り掛かかってしまいたいところですが、優先度は一番低く最後の最後で手をつける部分です。表層を改善するより一番下の層を改善するほうが効果がでることが多く、コスト対効果が高いです。
設定確認link
linux 編link
Linux 上で Node.js を運用するときにまず自分が気にするのは、プロセスが開けるファイルディスクリプタの上限数です。
Node.js は「ノンブロッキング I/O」や「非同期イベント駆動モデル」という特徴を持つ言語です。これに対して Apache などは1つのクライアントのアクセスに1つのプロセスを割り当てるモデルを採用しています。
一時期 C10K 問題が大きく話題に上がったことがありましたが、Node.js や Nginx は「ノンブロッキング I/O」や「非同期イベント駆動モデル」などを採用し、ひとつのプロセスで受けるクライアントの数を増やすことでこの問題に対処できます。
しかしこれらのモデルを採用したことで、逆にひとつのプロセスが同時にオープンするファイルも多くもなっています。それに伴い今度は OS 側が持っているプロセスが開けるファイルオープン数の上限に引っかかってしまう問題に直面することがあります。
そこでまずは ulimit コマンドで設定されている上限を確認します。例えば下記の例ではひとつのプロセスが同時にオープンできるファイル数は 1024 です。
$ ulimit -n
1024
この数値は Node.js にとって少なすぎます。このままではパフォーマンステストなどで高負荷をかけると Too many open files というエラーが高確率ででます。
自分は systemd を利用してシステムをデーモン化することが多いので LimitNOFILE の設定を忘れないようにしています。
[Service]
LimitNOFILE=65535
...
パフォーマンステスト中は頻繁にサーバを起動するので bash に起動コマンドを書くことも多いです。その時は bash の先頭で ulimit を使って上限を設定します。
#!/bin/bash
set -exuo pipefail
ulimit -n 65535
NODE_ENV=production node server.js
Node.js 編link
Node.js v12 から JSON.parse の高速化や async/await が Promise より高速化するなど、コアコードレベルで様々な高速化が行われています。まずは最新の LTS バージョンにあげることが Node.js アプリケーションでは重要です。参考
JavaScript は非常に後方互換性の高い言語ということもあり、Node.js はランタイムのバージョンアップでアプリケーションコードが大きく壊れてしまうことは少ないため積極的なアップデートがやりやすく、パフォーマンス対策という意味でも非常に有効な手段です。
Node.js v12 はその他にメモリの割当にも改善が行われました。Node.js v10 では起動時に 1400MB のヒープメモリが必ず確保されていましたが、v12 からは実行環境のメモリサイズに合わせたヒープサイズになるような改修が行われました。(これは近年の Kubernetes や Docker 上で動かす事を考慮した対応になります。)
しかし、これによって合計メモリサイズの低い環境では、今までより確保できるメモリサイズが少なくなってしまうことがあります。具体的には合計メモリサイズが 2.8GB 以下 の場合は Node.js v12 にバージョンアップすると最大ヒープサイズが半減します。
$ docker run --memory=1.5g -it node:10.19.0-alpine node -e 'console.log(Math.round(v8.getHeapStatistics().total_available_size/1024/1024) + " MB")'
1450 MB
$ docker run --memory=1.5g -it node:12.16.1-alpine node -e 'console.log(Math.round(v8.getHeapStatistics().total_available_size/1024/1024) + " MB")'
789 MB
そのためメモリの少ない環境で起動している場合は --max-old-space-size オプションを使って確保するヒープサイズを調整します。
$ NODE_ENV=production node --max-old-space-size=8192 server.js
cluster 対応link
デプロイ先の環境がマルチコア環境の場合は cluster モジュールを使ってマルチコア対応を行います。Node.js はそのままだとマルチコア環境でも1コアしか利用できません。
サンプルコードを下記に示しますが cluster モジュールによるマルチコア対応はとてもシンプルです。たったこれだけで fork 数倍のパフォーマンスを向上できます。非常にコスト対効果の高い対応と言えます。
const cluster = require('cluster')
const http = require('http')
const server = http.createServer()
if (cluster.isMaster) {
// コア数以内まで fork する
for (let i = 0; i < 4; i++) {
cluster.fork()
}
cluster.on('exit', (worker, code, signal) => {
const s = signal || code
console.log(`exit worker #${worker.process.pid} (${s})`)
cluster.fork()
})
} else {
server.listen(80, () => {
console.log('Listening on', server.address())
})
}
コア数全部 fork する場合は require('os').cpus().length でコア数を取得することもできます。
ここはシステムの運用方針にもよるのですが、コア数全部使い切ってしまうとアプリケーションが CPU 使用率 100% で張り付いてしまった場合に、何もできなくなってしまう危険性もあるのでサーバ内で動いているアプリケーションの数などサーバの構成によって調整してください。
プロファイリングlink
ここまできたらついにアプリケーションコードの改善に着手します。
Node.js 編link
Node.js には CPU のプロファイリングを行える --prof という起動オプションがあります。参考
$ node --prof index.js
このオプションをつけて起動しプロセスを終了すると isolate-xxxxx-xxxx-v8.log というファイルが吐き出されます。このファイルは人間が読み解くにはすこし難易度が高いので、さらにこのファイルを Node.js に食わせます。
$ node --prof-process isolate-xxxxx-xxxx-v8.log > isolate.txt
こうして吐き出された isolate.txt ファイルの中身を見てみます。
注目するべき場所は [Summary] です。ここは JavaScript や C++ レイヤーのコードがどれだけ CPU を専有しているかを表しています。
[Summary]:
ticks total nonlib name
0 0.2% 0.2% JavaScript
114 82.4% 89.6% C++
3 2.2% 2.4% GC
11 8.0% Shared libraries
13 9.4% Unaccounted
上記の例では C++ レイヤーの処理が全体の 80%を占めていることがわかります。つまり Node.js のコアコードが占める割合が多くあるということが読み取れます。
逆に JavaScript の割合が大きければ、アプリケーションにかかれている JavaScript 文法で書かれた部分が多くを占めるということになります。
コアコードの割合が大きかったら手を出せないじゃないかと思うかもしれませんが、これはアプリケーションコードやライブラリがコアコード(標準モジュール)を大量に呼び出していれば比率が高くなります。
例えば fs.readFilesync のような同期コードを呼ぶと、その処理中他の JavaScript コードは動くことができないので C++ の total 時間が加算されます。なのでコアコードだからといって改善できない訳ではありません。
GC はガベージコレクションが走ったことを表します。例えばここが 1453 6.0% 168.8% GC のように大量に呼ばれていた場合「頻繁な GC が起きている」=「メモリリークが起きてしまっている可能性がある」と読み解けます。
他にも Bottom up (heavy) profile の欄を見ると具体的にどういった関数が重い処理なのかを確認することができます。
[Bottom up (heavy) profile]:
Note: percentage shows a share of a particular caller in the total
amount of its parent calls.
Callers occupying less than 1.0% are not shown.
ticks parent name
78 39.4% T __ZN2v88internal40Builtin_CallSitePrototypeGetPromiseIndexEiPmPNS0_7IsolateE
34 43.6% T __ZN2v88internal40Builtin_CallSitePrototypeGetPromiseIndexEiPmPNS0_7IsolateE
18 52.9% LazyCompile: ~promise /tmp/index.js:14:23
18 100.0% T __ZN2v88internal40Builtin_CallSitePrototypeGetPromiseIndexEiPmPNS0_7IsolateE
18 100.0% t node::task_queue::RunMicrotasks(v8::FunctionCallbackInfo<v8::Value> const&)
18 100.0% LazyCompile: ~processTicksAndRejections internal/process/task_queues.js:65:35
2 5.9% T __ZN2v88internal40Builtin_CallSitePrototypeGetPromiseIndexEiPmPNS0_7IsolateE
1 50.0% t node::task_queue::RunMicrotasks(v8::FunctionCallbackInfo<v8::Value> const&)
しかし、この文字列情報だけでは多少見やすいとはいえ具体的にどこがヘビーなポイントなのかを読み解くのは容易ではありません。
そこで自分は flamegraph を利用してこれらの可視化を行っています。
flamegraph 編link
flamegraph は先にあげたコードパスの実行時間などをヒューマンフレンドリーに可視化してくれるツールです。これを通すことでホットコードなどが可視化され、どこを直すと効果が高いのかを見極めやすくなります。
flamegraph を表示するためのモジュールはいくつかありますが、自分は今は 0x というモジュールを利用しています。 これは Node.js のコアコミッターが作成しているモジュールなので、今後のバージョンアップにも追従していくだろうという予想から採用しています。
このモジュールをパフォーマンス検証環境にグローバルインストールします。
$ npm i -g 0x
インストールがすんだら 0x コマンド経由で Node.js を起動します。
$ 0x -- node index.js
そして起動した環境に vegeta で負荷をしばらくかけてから一度プロセスを終了します。
そうすると 4123.0x/ のようなディレクトリが生成されます。この中には先の --prof オプションで吐き出しされた isolate-xxxxx-xxxx-v8.log や flamegraph.html というファイルが格納されています。
今回注目するのは flamegraph.html です。これをブラウザで開くと次の画像のようなページが見られます。
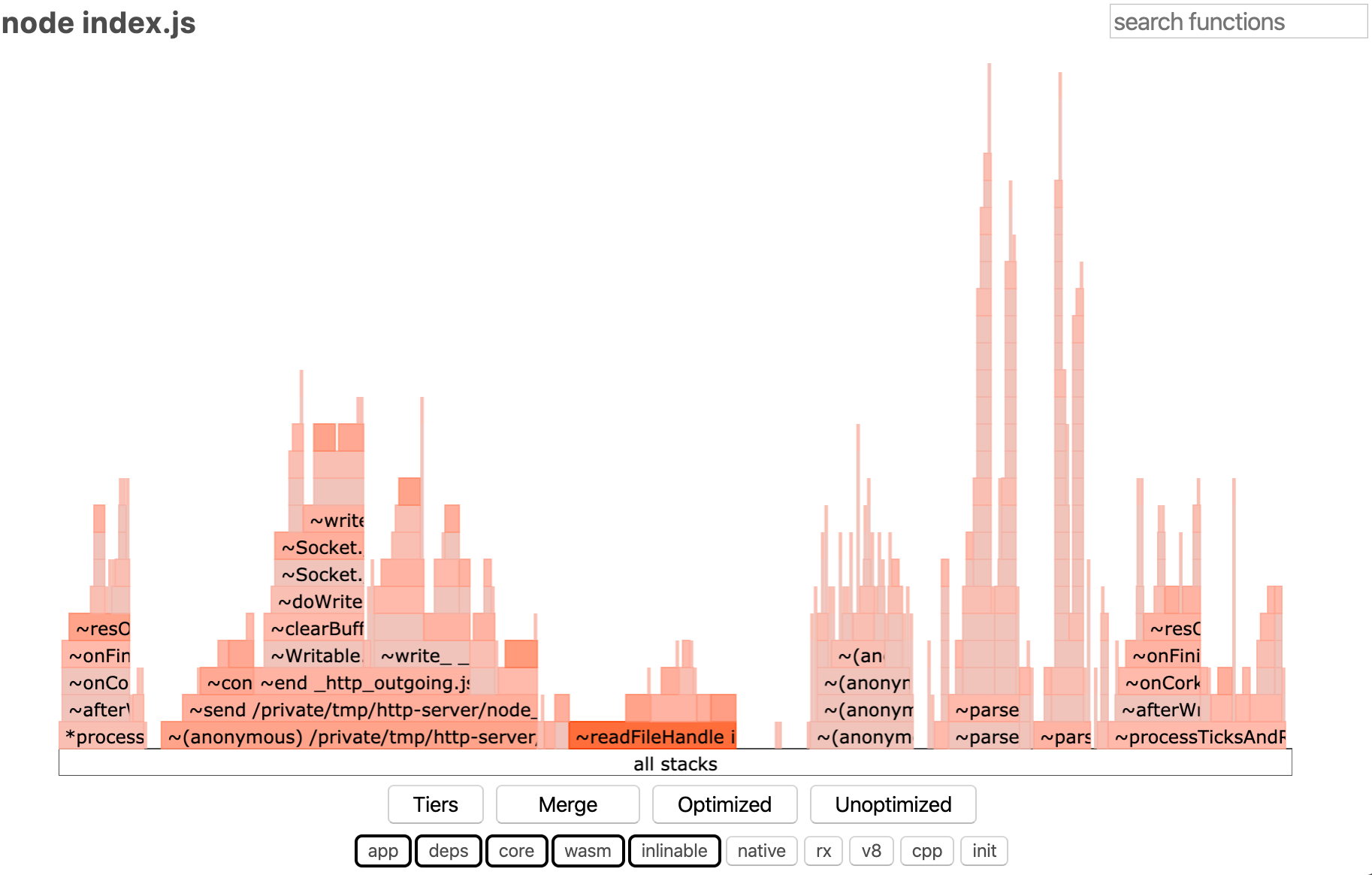
これは先程 --prof-process で吐き出した結果をよりグラフィカルに表したようなものです。濃い赤色になっているほどホットコード = 一番多く通るコードパスです。つまりこの濃い赤色の部分のパフォーマンスを向上させられると、全体に効果が出やすいわけです。
横軸は関数の実行時間を表し、その関数が呼び出した関数が上に積み上げられていきます。最初は縦に大量に積み上がっているとびっくりすることもあるかと思いますが、気にするべきは横幅です。「縦に積み上がっていて横幅が短い」のは「たくさん関数を呼び出しているが実行時間は短い」という意味になります。
なので最初は横幅が長くて、ホットコードな部分を重点的にみていくとよいと思います。
上の flamegraph は下のサンプルコードの結果です。
const path = require('path')
const fs = require('fs').promises
const express = require('express')
const app = express()
app.get('/', async (req, res, next) => {
try {
const html = await fs.readFile(path.join(__dirname, 'index.html'), {
encode: 'utf8'
})
res.status(200).send(html)
} catch (e) {
next(e)
}
})
app.listen(8000, () => {
console.log('listen')
})
flamegraph で一番赤くなっているとなっている部分をみると ~readFileHandle internal/fs/promises.js となっています。つまり fs モジュールの readFile という処理が多く動いているということがわかります。
上記のサンプルコードでいうとリクエストのたびに fs.readFile が走ってしまうためホットコードとして現れています。
この場合はリクエストによって返すファイルは変わらないので、サーバ起動時に一度だけファイルを読み込むようにすれば先程のようなホットコードの表示にはならないでしょう。
実際にはこんな単純に見つけられることはあまりないですが、俯瞰して眺めるのに利用します。まれに同期コードがホットコードして現れて一気に改善できることもあるので、右上にある検索ボックスにまず Sync と入れて検索をしたりします。
3. 具体的なパフォーマンスイシュー編link
パフォーマンスイシューはアプリケーションごとに異なる特有のコードなことが多いので、あまりこれといったパターンを示せないことが多いです。
とはいえ、自分が絶対に気をつけてみている観点はいくつかあります。こちらの資料に非常に詳しくまとまっていますが、これだけはどのアプリケーションでもパフォーマンスを下げてしまいがちな気をつけるべきポイントです。
- 巨大な JSON を扱う(JSON.parse/JSON.stringiy)
- 同期関数を使う(fs.readFileSync)
- 長いループが回っている
上記の処理に共通するのは「同期処理」です。Node.js では IO(ネットワークやファイル)に関わらない処理は基本的に同期処理となり CPU を専有します。
なので IO を伴わない処理をなるべく短くしていき「同期処理」を「細切れになるように」構築していくのがパフォーマンスを劣化させないコツになってきます。
それぞれ具体的に解説していきます。
巨大な JSON を扱うlink
JSON.parse/JSON.stringify は同期処理です。Node.js の同期処理はサーバのリソースをそれのみに集中してしまうため、その処理中は他のリクエストを捌くことはできません。
JSON の処理は JSON の大きさに比例して停止時間が長くなります。これは特に SSR/BFF などのサーバでボトルネックになりがちです。
例えば React の SSR であれば最後に state オブジェクトを文字列化して html に渡しますが、ここの JSON が大きければもちろんサーバの停止時間は長くなります。
これを解消するためには、そのページで同期的にレンダリングしなくてもよい箇所はブラウザに任せて非同期に描画し、不要な state を外してレンダリングに必要な JSON を小さくします。
他にもバックエンドの API を叩いて SSR を行うというのはよくあるケースだと思いますが、この際にバックエンドから返却される JSON が大きく、リクエストのたびに JSON.parse が走りその都度サーバがストップしてしまっていることがよくあります。
自分では JSON.parse を書いているつもりはなくても axios などのリクエストモジュールを利用しているとモジュール内部で JSON.parse が行われていたりします。
この影響を少なくするためには基本的に JSON を小さくするか JSON.parse 自体の数を減らすしかありません。
- なるべくキャッシュして JSON.parse が起きないようにする
- エントリポイントを分割して 1 つずつを小さくする(ページングや ID だけの配列からリクエストを分割して叩くように設計するなど)
どれくらいの大きさから大きいというのかは難しい問題ですが、目安としては「最大でも 1MB 以内」に収まるあたりがよいと思います。
また、API を作成した時点では小さい JSON だったけど、データ量が増えるにつれて比例して肥大化していった(配列でデータを返しているパターンが多い)ということもあるので、API 設計時点で将来も肥大化しない設計であることは重要です。
Node.js v12 で JSON.parse はかなり高速化していますが、それでも気をつけるべきなのは間違いありません。
同期関数を使うlink
こちらも理屈は JSON と同じで、同期処理中は他のリクエストを捌けないため、リクエストのたびに通るコードパスからはなるべく避ける必要があります。
~Sync とついていたら危ないかも?と思っておくとよいかもしれません。
const fs = require('fs')
app.get('/', (req, res) => {
// ここでサーバがストップする
const html = fs.readFileSync('./index.html')
res.status(200).send(html)
})
もちろん絶対に使ってはいけないというわけではなく、リクエストのたびに通らないコードパスであれば問題ありません。
const fs = require('fs')
// ここでサーバがストップするが、サーバ起動時に一度だけしか動かないので問題ない
const html = fs.readFileSync('./index.html')
app.get('/', (req, res) => {
res.status(200).send(html)
})
どうしてもリクエストのたびに通るパスで使いたい、というときは基本的には非同期処理の関数が用意されているはずなのでそちらを利用しましょう。
Node.js のコアモジュールは callback 形式になっていることが多いですが、最近は Promise のインターフェースも生えています。
const fs = require('fs').promises
app.get('/', (req, res) => {
fs.readFile('./index.html').then((html) => {
res.status(200).send(html)
})
})
長いループが回っているlink
これも先の例と同様に同期処理です。長い配列をループで回している間はサーバが停止します。ループは先の例に比べて避けるのが難しい処理でが、緩和する方法はいくつかあります。
例えば1万件のデータが入っている Redis の key を取得して、それぞれに処理を行い返すようなエンドポイントがあったとします。(API 設計の時点でページングしたほうがよいのは確かですが例として)
下記のようなコードだと、レスポンスを返す直前にループ処理をしてしまうので、その間リクエストを受けることができません。
const redis = new Redis()
app.get('/', (req, res) => {
const keys = []
// データを100件ずつ取得する stream を作る
const stream = redis.scanStream({ count: 100 })
// 100件取得したら keys に詰め込む
stream.on('data', (results) => {
for (let i = 0; i < results.length; i++) {
keys.push(results[i])
}
})
stream.on('end', () => {
// keys.map が1万件のループになるので長時間の停止になってしまう
res.status(200).json(keys.map((e) => `key-${e}`))
})
})
例えばこの場合は data イベントの中で整形処理をするべきです。
const redis = new Redis()
app.get('/', (req, res) => {
const keys = []
// データを100件ずつ取得する stream を作る
const stream = redis.scanStream({ count: 100 })
// 100件取得したら keys に詰め込む
stream.on('data', (results) => {
for (let i = 0; i < results.length; i++) {
keys.push(`key-${results[i]}`)
}
})
stream.on('end', () => {
// 整形が終わっているのでループは回らない
res.status(200).json(keys)
})
})
このように、大量のループを回さなければならない場合でも、間に IO を挟むことで細切れにできる可能性があります。
Stream 処理は難しいと思われがちですが、大量の処理を省メモリで行うのに適したデザインパターンなので覚えておいて損はありません。
特に Node.js v12 では AsyncIterator も Stable になっているので記述がしやすくなっています。
Stream については過去に記事を書いたので、そちらをご参照ください。さよなら Stream
4. メモリリーク調査編link
前項で述べてきたパフォーマンスチューニングは主に設計やアプリケーションの書き方によるパフォーマンス低下をみつける手法でした。
Node.js が性能を劣化させる原因のもうひとつにガベージコレクションがあります。基本的に他の言語と同様にガベージコレクションはランタイムを停止させてしまうため、性能上よくありません。
プロファイリングの項で少し触れましたが、プロファイリングからガベージコレクションがどれくらいの頻度で走っているかを取得することができます。
ガベージコレクションが大量に起きていたり、もしくはサーバの監視で右肩上がりをしていたメモリ使用量が突然下がってまた上昇していく、といった特徴が出ていた場合、コード中にメモリリークしているコードが含まれている可能性があります。
基本的に Node.js のコアコードにメモリリークは存在しません。メモリリークが起きてしまっているということはほぼ確実に「自分の書いたコード」か「利用しているモジュール」に原因があります。
ここでは実際に自分が体験した material-ui の使い方で起きていたメモリリークの例をもとに、調査の方法をまとめたいと思います。
リークが起きていることを確認link
実際にメモリリークが起きているかを確認するためには、やはり計測してみるしかありません。次のようなコードを差し込んでみます。
setInterval(() => {
try {
global.gc()
} catch (e) {
console.log('use --expose-gc')
process.exit(1)
}
const heapUsed = process.memoryUsage().heapUsed
console.log('Heap:', heapUsed, 'bytes')
}, 2000)
global.gc は強制的に GC を呼び出す関数です。heap メモリの使用量を出力する前に GC を走らせてもメモリ使用量が上がり続けていれば GC できない領域にメモリを掴み続けている(メモリリークがある)可能性があります。
この関数を利用するためにはフラグ付きで起動する必要があります。
$ node --expose-gc index.js
実際にメモリリークが起きているサーバで起動してみると、右肩上がりにヒープが使われていくのがわかります。
Heap: 137273608 bytes
Heap: 144623352 bytes
Heap: 146617720 bytes
Heap: 146791344 bytes
Heap: 146827544 bytes
Heap: 146838568 bytes
Heap: 146988200 bytes
Heap: 131588016 bytes
Heap: 213734336 bytes
Heap: 338640232 bytes
Heap: 471909552 bytes
Heap: 394506192 bytes
Heap: 515059296 bytes
Heap: 617747056 bytes
Heap: 720730040 bytes
Heap: 821192400 bytes
Heap: 924329760 bytes
Heap: 957664088 bytes
Heap: 957814288 bytes
Heap: 957840840 bytes
Heap: 957848128 bytes
もちろん普通のアプリケーションも時間経過とともにメモリ消費は増えるものなので、右肩上がりだからといって即座にメモリリークと判断するのは危険です。先に述べたような特徴と合わせて事前にメモリリークが起きているかどうかを判断しましょう。
しかしこれだけでは具体的に何がメモリリークを起こしているのかはわかりません。
なので、次はメモリのヒープダンプをとります。
ヒープダンプの取得link
Node.js でメモリを直接調査する方法はくつか方法がありますが heapdump モジュールを使う方法が手軽です。
少し昔の記事ですが、こちらで紹介されているメモリリークの発見ガイドは非常に参考になるので必読です。
基本的に行うことは上記の記事にある「3点ヒープダンプ法」です。
自分は下記のようなコードを差し込み外から kill コマンドを送って3回ヒープダンプを取得します。
require('heapdump')
process.on('SIGUSR2', () => {
console.log('heap dump start!')
heapdump.writeSnapshot()
console.log('heap dump end!')
})
$ kill -USR2 {{pid}}
このとき SIGUSR1 を割り当てないのには理由があります。
SIGUSR1 は Linux 的にはユーザーが自由に使っていいシグナルになっていますが、Node.js では debugger を起動するシグナルとして利用されています。詳細
イベントにハンドラーをバインドすることはできますが debugger が起動してしまうので避けたほうがいいでしょう。
話は戻って heapdump モジュールを利用して heapdump.writeSnapshot() を実行すると heapdump-xxxx というファイルが取得できます。
次に Chrome の開発者ツールを開き Profiles タブを開いて Load ボタンからファイルをロードしていきます。
下の図が実際に調査を行ったときのスクリーンショットです。
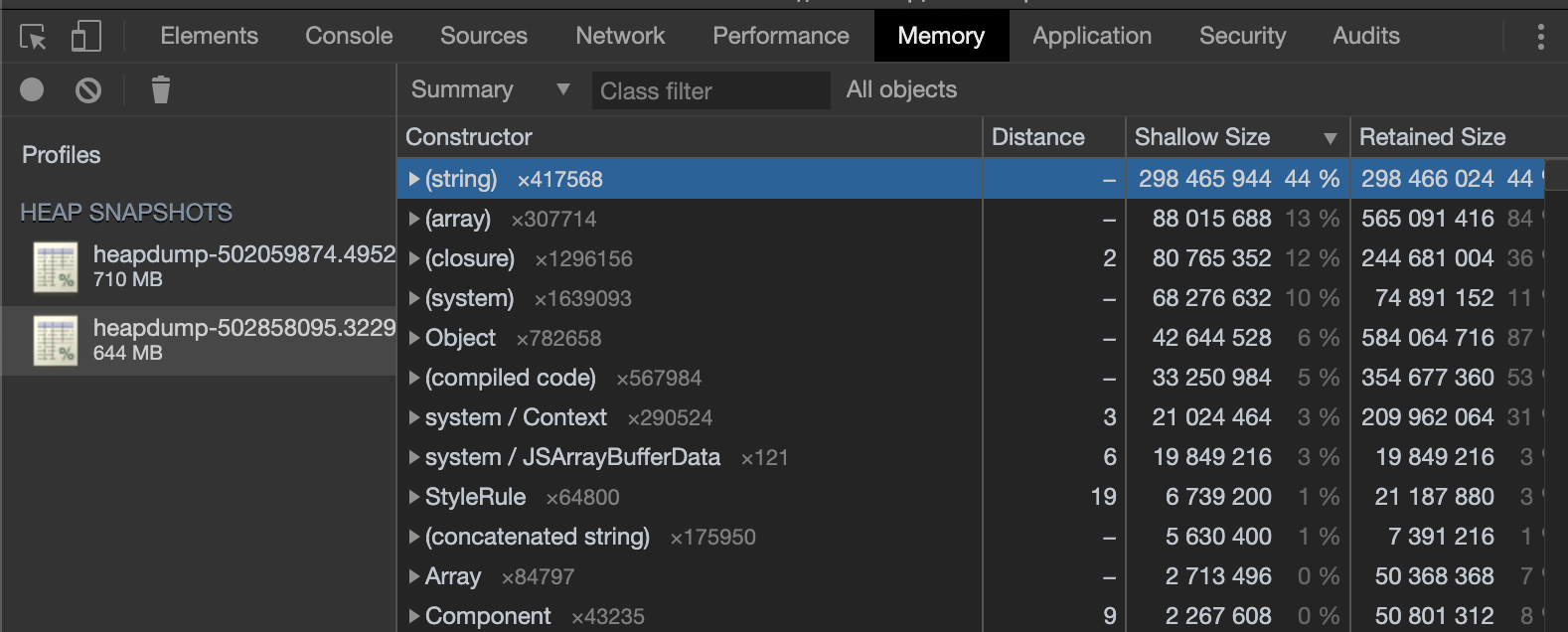
先の記事で解説されている3点ヒープダンプ法は All objects となっているところから Objects allocated between heapdump-xxx and heapdump- を選択して、 heapdump 間で新しくアロケートされメモリの上に GC されずに残ってしまっているオブジェクトを探すことで、どのオブジェクトがメモリリークを起こしているのかを知る方法です。
しかし、今回の計測の結果では3点ヒープダンプ方を使ってメモリリークを見つけることはできませんでした。
ではどこに注目したかというと (string) という表記です。
先の記事では「少なくとも最初は(string)を無視する」と書いてありますが、今回調査していたサーバは SSR の機能を担うだったことと、明らかに他のオブジェクトに比べて大きなメモリを消費していたので気になりました。
(string) の左にある三角を押すと実際に参照している関数やオブジェクトなどが展開されます。実際に追ってみると大量の StyleSheet というオブジェクトが (string) を参照していることがわかりました。実際にメモリの中身を覗いてみると、ほぼ style の文字列情報でした。
ということでスタイル系の処理がリクエスト終了後も文字列を掴み続けてしまっているのではないかと当たりをつけて、先程のオブジェクトがどこで生成されているかを調べてみると material-ui が生成していることがわかりました。
さらに StyleSheet memory leak で issue を調べてみると次の issue で同じ現象になっている人をみつけました。
issue 内のコードと実コードを見比べてみると sheetsManager という props を渡していないことがわかり、これを加えることでメモリリークは解消しました。
<StylesProvider
sheetsRegistry={registry}
generateClassName={generateClassName}
+ sheetsManager={new Map()}
>
(蛇足ですが、ドキュメントにそんな記載があったかなと探しては見ましたが、うまく記述が見つけられませんでした。確かにコードを眺めてみると、NODE_ENV=production以外の時に sheetsManager が与えられていないと警告のログが出るようになっていましたが、今回のケースでは本番環境相当で起動していたため気づけませんでした。)
このようにヒープダンプを追っていくことで、原因の特定に役立つことがあります。
まとめlink
自分が Node.js のパフォーマンスチューニングでいつも見ている点や方法をまとめました。
パフォーマンスイシューはアプリケーションによって異なるため、地道な計測と調査が必要になりますが、やった数だけ確実に勘所がつくようになります。
自分もいくつかの環境を見ることである程度勘が働くようになってはきましたが、まだまだたくさんの事例をみないといけないなと毎回思います。
Twitter などで声をかけていただければ、実際のアプリケーションコードを見ながら調査のお手伝い等もできるので、ぜひ一緒に知見をためましょう!