kohsweblog
Lighthouse CIでサイトのスコアを定期的にチェックしよう

Core Web Vitals とはlink
最近のフロントエンド周辺では Google が提唱した Web Vitals と呼ばれる指標が非常に注目されています。
これは Web で多くのユーザーが快適なユーザー体験を得るために、こういったポイントに特に気を使いましょう、というものを数値化したものです。
この中でも特に重要と定められている “LCP (Largest Contentful Paint)”, “FID (First Input Delay)”, “CLS (Cumulative Layout Shift)” の 3 つは Core Web Vitals と呼ばれています。
それぞれの観点を簡単に説明すると次のようになります。
- LCP: 重要な要素がどれだけ早く読み込まれたか
- FID: 最初の入力ができるまでにどれくらいかかったか
- CLS: がくっとレイアウトが変わることがないか
Ref: Web Vitals の概要: サイトの健全性を示す重要指標
例えば製品を説明するページのヒーローイメージのサイズがとても大きく、読み込みに時間がかかったらユーザーはがっかりして離脱してしまうかもしれません。それを表した指標が LCP だと思ってください。
例えば JavaScript を使ったとてもリッチな表現で見た目のよいシステムを作ったとします。しかし JavaScript を処理し終わるまで検索バーが使えなかったらとても使いにくいシステムと思われてしまうでしょう。FID はいかにシステムの機能を最速でユーザーに届けるという指標です。
実際にスマホなどでページを読み込んでいる最中に、突然広告が読み込まれて変なところをタップしてしまったという経験はないでしょうか。そのイライラをユーザーに与えてしまっていないかを数値化した指標が CLS です。
もちろんこれらのスコアが全てではないですが、これらのスコアを上げることができればユーザーにとって快適に近づくというのはイメージしやすいのではないでしょうか。
また Google は Chrome 上でバッヂをつけることで、高速なサイトと低速なサイトを見分けられるようにし、高速なサイトを優遇すると述べています。(Android 版の Chrome では chrome://flags から Context menu performance info and remote hint fetching フラグをオンにすることで、すでにこの機能が利用可能です。)
Ref: さらに高速なウェブへの移行に向けて
![]()
Core Web Vitals の計測link
言葉にしてしまえばどの指標も当たり前のように聞こえてしまう話ですが、これら全てをシステムを作っている段階で気にしながら開発するのは非常に難易度が高いことです。そこで、これらのスコアを特定のタイミングで可視化することが重要になります。
そのためにいくつかのツールが提供されています。
CrUX, SearchConsolelink
先程の指標は実際に(Chrome を利用している)ユーザーがどのような影響を受けたかを集めたデータ(フィールドデータ)によって計測されます。
これらのデータを集計、サマライズしたものを Chrome User Experience Report (CrUX) のダッシュボードで参照することができます。
Ref:
また、SearchConsole を利用している場合は「ウェブに関する主な指標」から同様のデータを参照することが可能です。
しかしこれらのツールはフィールドデータを利用している事で弱点も生まれます。そう、例えばこのブログのように十分な匿名データが集まらない程度の PV しかないサイトでは、悲しいことにデータ量が少なすぎて表示できません。
とはいえ悲しんでばかりもいられないので他の方法でスコアを計測します。
PageSpeed Insights, Lighthouselink
では十分フィールドデータが集められない環境ではどうやってスコアを計測するのか。ここで登場するのが PageSpeed Insights や Lighthouse です。
これらのツールはフィールドデータではなくラボデータ、つまり実行したタイミングでそのツールが計測した値を元にスコアリングを行います。
昔は Chrome の拡張として提供されていた Lighthouse ですが、最近は Chrome の開発者ツールにバンドルされています。
PageSpeed Insights は Lighthouse を Web 上で実行できるプラットフォームと思って貰えれば大丈夫です。PageSpeed Insights では十分なフィールドデータがある場合、フィールドデータとラボデータの両方が同時に確認可能です。
PageSpeed Insights はインターネット上でアクセスできる URL がなければ利用できませんが、Lighthouse はブラウザにバンドルされているため、インターネットから隔離された社内環境等でも計測が可能です。
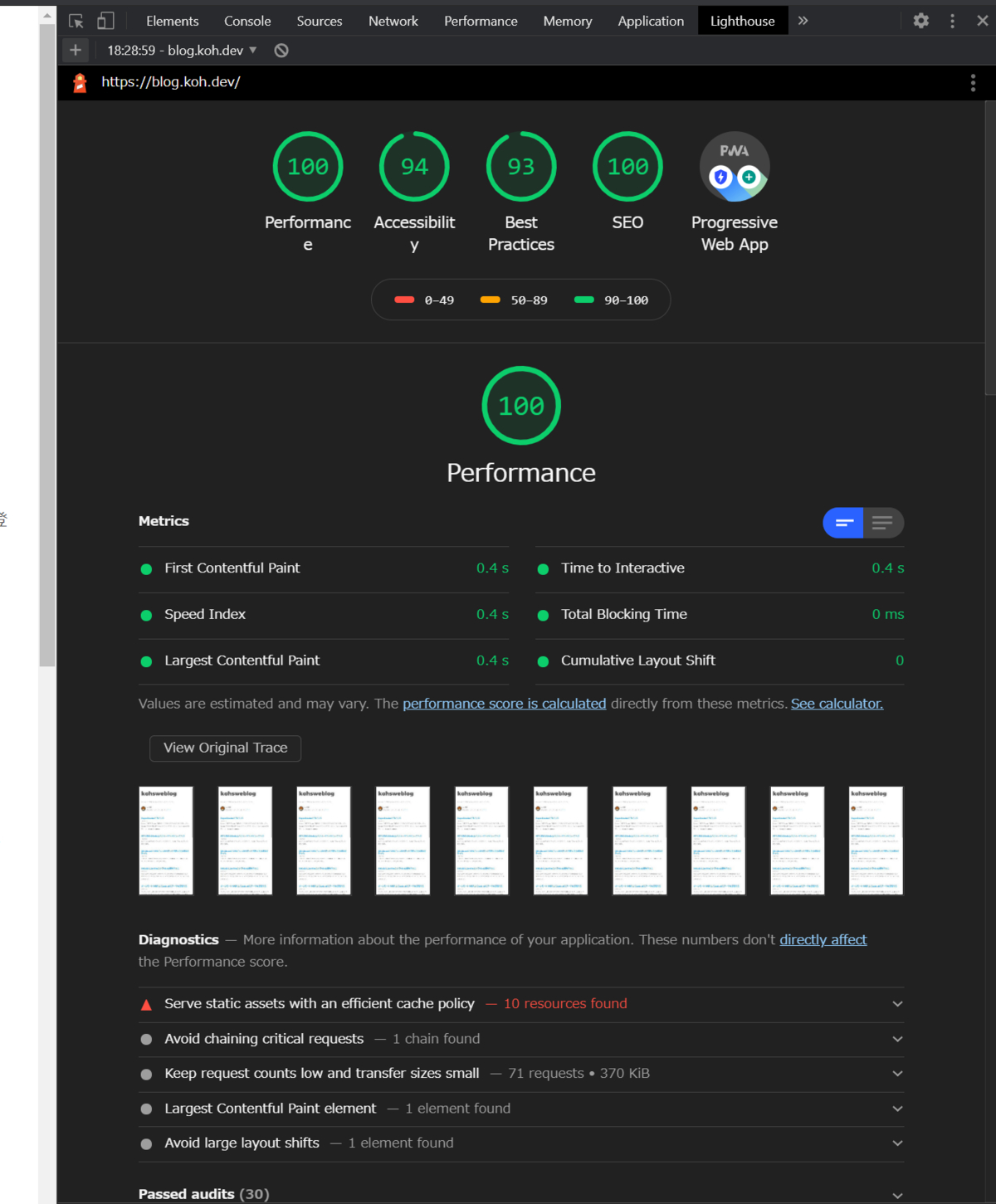
Lighthouse は各指標で具体的にどれくらいの時間がかかったか、それから計算されるスコアはいくつかなどが確認可能です。さらにその結果から具体的にこの部分を直しましょうというアドバイスまでしてくれます。
例えばページの中で大きな画像が読み込まれていれば「この画像のフォーマットを変えたり、サイズを縮小しましょう」となったり、利用していない JavaScript が読み込まれていれば「利用していない JavaScript を削除しましょう」と具体的なファイル名を教えてくれる、といった具合に直すべき箇所をあげてくれます。
実際にスコアを上げる際には Lighthouse に何度もお世話になる事になるでしょう。
Ref:
ラボデータはデータ量が十分に集まっていない状態でもスコアを算出することができることがメリットです。逆にいうと計測環境のネットワークや CPU にスコアが左右されやすいということに考慮が必要です。
また、これらのスコアは一度測ればいいものではなく、常に計測を続けて追加した機能などでスコアが低下していないか、などスコアの推移を見ることで効果を発揮するものです。そのためにも一定のタイミング/性能で計測を続けたくなります。
つまり CI に組み込んだり、cron で回したくなるのが自然な発想でしょう。それを実現するために Lighthouse をラップした Lighthouse CI というツールが提供されています。
Lighthouse CI の構築link
Ligthouse CI とは Lighthouse を CI のステップに組み込むことができるツールです。データを貯め込み可視化する server と、計測を行って server に送信する cli の 2 つのパッケージから構成されています。
https://github.com/GoogleChrome/lighthouse-ci
実際にどのようにして Lighthouse CI を構築・運用していくのかを、Ubuntu 上で実行しながら解説していきます。
Lighthouse CI Server の構築link
Server の構築方法を簡単にまとめると次の 3 ステップになります。公式の手順はこちらです。
- Node.js のインストール
- MySQL のインストール
- Server アプリケーションの作成
Lighthouse は Node.js で動くので Node.js を最初にインストールしてください。自分はさくっとインストールする時は次のようなスクリプトを使って構築することが多いです。
Ref: Ndoe.js のインストール
次は MySQL のインストールです。Lighthouse CI Server は MySQL の他に SQLite や PostgreSQL でも動作します。今回は自分が使い慣れている MySQL を選択しました。 内部的には Sequelize を利用しているようです。
$ sudo apt install mysql-server mysql-client
$ sudo service mysql status
$ sudo mysql -u root
# password は適切な文字列を利用してください
mysql> CREATE USER 'lighthouseuser'@'localhost' IDENTIFIED BY 'password';
mysql> GRANT ALL ON lighthouse.* TO lighthouseuser IDENTIFIED BY 'password';
mysql> CREATE DATABASE lighthouse;
MySQL を使って運用している場合、計測結果のアップロード時に Server 側にエラーが出ることがあります。
SequelizeDatabaseError: Incorrect string value: '...' for column 'lhr' at row 1
MySQL のエンコーディングが utf8 の場合サロゲートペア文字が扱えないため、MySQL 側の設定を utf8mb4 に変える必要があるようです。
mysql> show variables like "chara%";
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
/etc/mysql/my.cnf に次の設定を追加しています。
[mysql]
default-character-set=utf8mb4
[mysqld]
character-set-server=utf8mb4
上記の設定を追加して MySQL サーバーを再起動すると文字コードが変わっていることがわかります。
mysql> show variables like "chara%";
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
最後にアプリケーションの作成を行います。とは言っても config ファイルを用意して cli から起動するだけです。
$ cd lighthouse-ci-server
$ echo "{ \"private\": true }" > package.json
$ npm install -D npm install -D @lhci/cli @lhci/server mysql2
$ touch lighthouserc.js
$ tree -L 1
.
├── lighthouserc.js
├── node_modules
├── package.json
└── package-lock.json
1 directory, 3 files
最初はちょっとわかりにくいのですが、Server も CLI も同じ lhci コマンドを使って起動できます。
サーバーの config 設定はこちらを参考にします。
lhci は内部的に yags に依存しているので、オプションでそれぞれの値を設定することもできます。また、モジュールを読み込んで普通のアプリケーションサーバーのように Node.js のスクリプトで起動することもできます。
const { createServer } = require('@lhci/server')
console.log('Starting server...')
createServer({
port: process.env.PORT,
storage: {
storageMethod: 'sql',
sqlDialect: 'sqlite',
sqlDatabasePath: '/path/to/db.sql'
}
}).then(({ port }) => console.log('LHCI listening on port', port))
Ref:
サーバーの設定に必要なパラメーターはドキュメントもありますが型定義が提供されているので、ここを参照したほうがわかりやすいと思います。
lighthouserc.js の中身は次のようになります。
const sqlConnectionUrl = `mysql://${process.env.MYSQL_USER}:${process.env.MYSQL_PASSWORD}@localhost/lighthouse`
module.exports = {
ci: {
server: {
port: process.env.PORT,
storage: {
storageMethod: 'sql',
sqlDialect: 'mysql',
sqlConnectionUrl
}
}
}
}
設定ファイルを配置したらサーバーを起動してブラウザの表示を確認してみましょう。
$ PORT=3000 MYSQL_USER=lighthouseuser MYSQL_PASSWORD=password ./node_modules/.bin/lhci server --config=./lighthouserc.js
ブラウザで開いてみると初期画面として次のような画面が表示されます。
MySQL 側を確認してみると必要なテーブルが自動で生成されています。
mysql> use lighthouse;
mysql> show tables;
+----------------------+
| Tables_in_lighthouse |
+----------------------+
| SequelizeMeta |
| builds |
| projects |
| runs |
| statistics |
+----------------------+
5 rows in set (0.00 sec)
サーバーの動作を確認したらデーモン化します。自分はプライベートでさくっとやる時には systemd をよく使います。
[Unit]
Description=lighthouse ci server
[Service]
Type=simple
Environment=PORT=3000
Environment=MYSQL_USER=lighthouseuser
Environment=MYSQL_PASSWORD=password
WorkingDirectory=/var/lighthouse/lighthouse-server
ExecStart=/var/lighthouse/lighthouse-serve/rnode_modules/.bin/lhcilhci server --config=/var/lighthouse/lighthouse-server/lighthouserc.js
User=root
Group=root
Restart=always
LimitNOFILE=65535
TimeoutStopSec=60
[Install]
WantedBy=multi-user.target
次は CLI で実際にスコアを計測して Server に登録してみます。
Lighthouse CIlink
実際に CI がデータを Server に登録するまでには 3 ステップの処理を行います。
- collect: 実際にサイトの計測を行うステップ
- assert: スコアが特定値より低い時にエラーを起こすステップ
- upload: 結果を Server に登録するステップ
この 3 ステップをまとめて autorun として実行することもできます。 もともと Lighthouse CI は GitHub Actions や Circle CI など CI に組み込むことを想定して作られています。
今回はコミットごとの計測ではなく、定点観測を行う環境を構築するため assert ステップは飛ばして実行します。
ともあれ、まずは CLI を使えるようにしないことには始まらないのでグローバルにインストールしてパスを通します。
記事執筆時点での最新バージョンは 0.5.1 です。
# サーバーにインストールされている lhci のバージョンを調べる
$ curl https://your-lhci-server.example.com/version
$ npm install -g @lhci/cli@latest
$ lhci --version
0.5.1
Lighthouse CI はプロジェクトという単位で複数の URL を管理することができます。
なので計測をする前に、まず最初はプロジェクトの作成から入ります。lhci wizard コマンドを叩くと対話形式でプロジェクトの作成ができます。
lhci wizard の実行が完了すると Server にプロジェクトを登録し build token と admin token を発行します。
$ lhci wizard
? Which wizard do you want to run? new-project
? What is the URL of your LHCI server? http://localhost:3000
? What would you like to name the project? kohsweb
? Where is the project's code hosted? https://github.com/koh110/lighouse-kohsweb
? What branch is considered the repo's trunk or main branch? master
Created project kohsweb (9498cd1d-02e5-4418-a974-bda42c4513e0)!
Use build token xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx to add data.
Use admin token xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx to manage data. KEEP THIS SECRET!
Server の UI を見に行くとプロジェクトが登録されています。

先程発行された admin token を使って画面上から、プロジェクトの設定の変更や削除が可能です。
build token は upload ステップで Server にデータを登録するために必要となります。
collectlink
まずは Server と同様に lighthouserc.js を用意します。設定項目は CLI のオプションからも渡すことはできます。複数のプロジェクトで共通する設定などをコンフィグで管理し、変動する値を CLI のオプションで渡すのがよいのではないかと思います。
ひとまずサンプルとして numberOfRuns を設定してみましょう。Lighthouse は通信状況やアプリケーションの状態によってもスコアが変わってくるので、デフォルトで 3 回繰り返して計測します。それを 5 回実行してコンフィグファイルの挙動を確認してみます。
Ref: collect の設定項目
module.exports = {
ci: {
collect: {
numberOfRuns: 5
}
}
}
うまく動作すると 5 回実行されることが確認できます。
$ lhci collect --url=https://blog.koh.dev --config=./lighthouserc.js
Running Lighthouse 5 time(s) on https://blog.koh.dev
Run #1...done.
Run #2...done.
Run #3...done.
Run #4...done.
Run #5...done.
Done running Lighthouse!
GUI 環境であれば計測した結果をブラウザで確認することが可能です。計測結果は .lighthouseci/ ディレクトリに保存されていて、ここの html を開いてくれます。
$ lhci open
Opening median report for https://blog.koh.dev/...
Done!
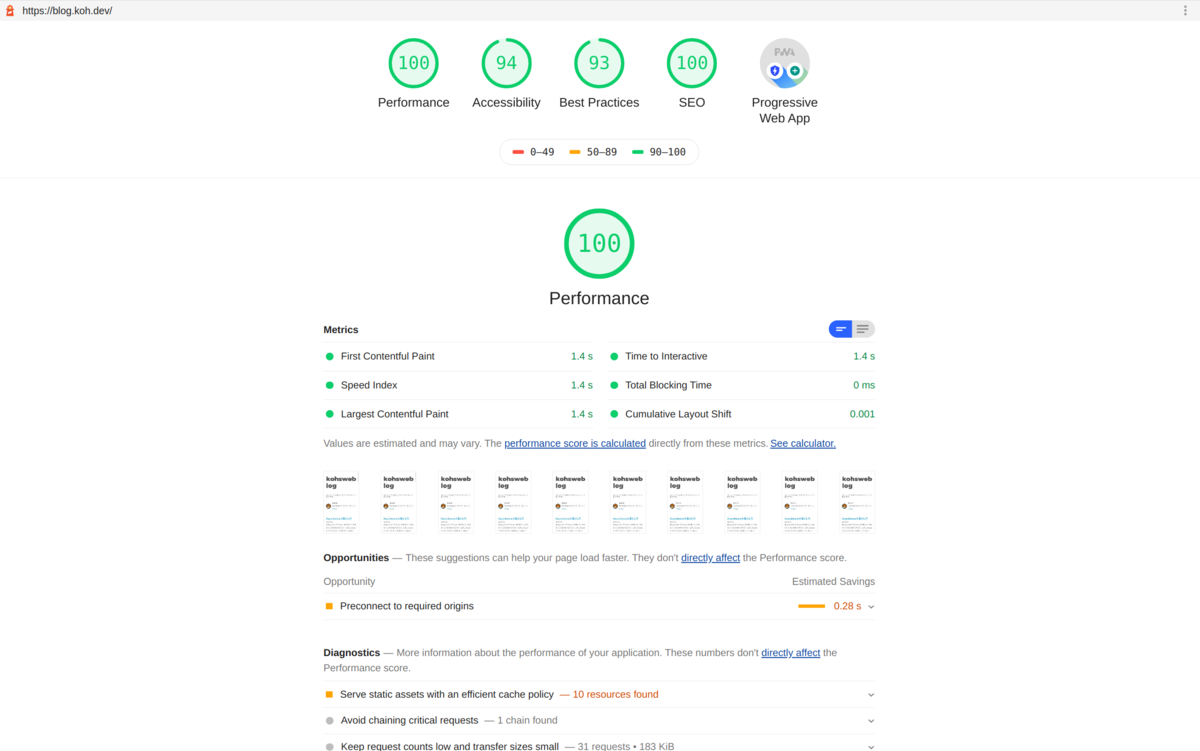
GUI 環境でない場合は Chrome が実行できなくて失敗することがあります。Chrome をインストールしてもよいですが、puppeteer モジュールの中にバンドルされている Chrome を使うのが楽だと思います。
$ npm i puppeteer
const puppeteer = require('puppeteer')
module.exports = {
ci: {
collect: {
chromePath: puppeteer.executablePath(),
numberOfRuns: 5
}
}
}
url オプションは複数回指定することで複数同時に計測できます。
$ lhci collect --url=https://blog.koh.dev --url=https://koh.dev --config=./lighthouserc.js
これで計測は完了、としてしまってもいいですが実は Lighthouse CI はデフォルト値がスマホに合わせてあるため、このままではスマホ環境しか計測できません。
Lighthouse はスマホ環境を計測する場合は CPU やネットワークを擬似的に遅くしてスマホでの動作をエミュレートしています。
では具体的にどこのオプションを切り替えればいいかというと settings オプジェクトの emulatedFormFactor を修正することで変更が可能です。
$ lhci collect --url=https://blog.koh.dev --settings.emulatedFormFactor=desktop --config=./lighthouserc.js
settings オブジェクトが具体的にどんなオプションを受け付けるのかは Lighthouse の型定義ファイルをみてくださいということになっています。この辺はちょっとドキュメントが簡素で迷うことがありますね。
Ref: settings
さあこれでデスクトップ環境も計測できるようになった、と思うと実はまだこれだけでは Chrome に内蔵されている Lighthouse とはスコアに差が出ます。(ネットワークの状況や計測環境のスペックによってもスコアは変わるのでスコアが違ったからといって一概に間違ってるとは言えませんが)
emulatedFormFactor は Lighthouse の UserAgent しか変更しないので、ネットワークや CPU のエミュレートはスマホ向けの値のままなので、Chrome 内蔵の Lighthouse の Desktop を計測した時と同じような値を取得するためにはその値に変更する必要があります。
具体的にそれらの値がどこで管理されているかを探してみると Ligthouse のリポジトリ内で定義されています。
これらのエミュレートする値は throttling オブジェクトで与える事ができるので、リポジトリ内の数字を参考に渡してあげることで、やっと Chrome 内蔵の Lighthouse と同じような挙動が可能になります。
$ lhci collect --url=https://blog.koh.dev --settings.emulatedFormFactor=desktop --settings.throttling.cpuSlowdownMultiplier=1 --settings.throttling.throughputKbps=10240 --settings.throttling.rttMs=40 --config=./lighthouserc.js
定期的に動かす環境ではスコアを変動させる要因は少なくしたほうがよいので、今後のアップデートで値が変更される可能性も考えると Mobile の場合も固定値で指定したほうがよいかもしれません。
$ lhci collect --url=https://blog.koh.dev --settings.emulatedFormFactor=mobile --settings.throttling.cpuSlowdownMultiplier=4 --settings.throttling.throughputKbps=1638.4 --settings.throttling.rttMs=150 --config=./lighthouserc.js
ここまでで計測するコマンドを作ることができるようになりました。次はこの結果を Server にアップロードしてみましょう。
uploadlink
upload ステップでやっている事は .lighthouse/ の内容を参照してターゲットとなる Server にアップロードするだけです。
言葉にすると非常にシンプルですが、時間をトリガーにしてスコアの定点観測を行うためには少し工夫が必要になります。
Lighthouse CI が想定しているのは GitHub のコミットに紐づけて、そのコミットによってスコアが変化したかどうかを CI でテストするという使い方です。 なので、Server に登録する際にはコミットハッシュなどの情報が必要になります。これらの情報は環境変数からコマンドに渡すことができるので、uplaod コマンドを実行する際に渡してあげます。
もし環境変数を与えないまま単純に手元で実行しようとするとエラーがおきると思います。
$ lhci upload --config=./lighthouserc.js --token=xxxxxxxxxxxxxxxxxx
Error: Unable to determine current hash with `git rev-parse HEAD`. This can be overridden with setting LHCI_BUILD_CONTEXT__CURRENT_HASH env.
at getCurrentHash (/usr/local/lib/node_modules/@lhci/cli/node_modules/@lhci/utils/src/build-context.js:74:11)
upload コマンドを実行するために、まずは先程の lighthouserc.js に upload 用の設定を加えます。
const puppeteer = require('puppeteer')
module.exports = {
ci: {
collect: {
chromePath: puppeteer.executablePath(),
numberOfRuns: 5
},
upload: {
target: 'lhci',
serverBaseUrl: 'http://localhost:3000'
}
}
}
自分は次のようなシェルスクリプトを作って利用しています。こちらの issue に記載されている方法をほぼ踏襲しながら、CURRENT_HASH や COMMIT_TIME の生成のコードを Node.js によせて少し書きかえています。
export TZ="Asia/Tokeyo"
export LHCI_BUILD_CONTEXT__CURRENT_HASH=$(node -e "console.log(crypto.createHash('md5').update(Date.now().toString()).digest('hex'))")
export LHCI_BUILD_CONTEXT__COMMIT_TIME=$(node -e "console.log(new Date().toISOString())")
export LHCI_BUILD_CONTEXT__CURRENT_BRANCH=master
export LHCI_BUILD_CONTEXT__COMMIT_MESSAGE="Periodic run $(node -e "console.log(new Date().toISOString())")"
export LHCI_BUILD_CONTEXT__AUTHOR="kohta ito <koh110@example.com>"
export LHCI_BUILD_CONTEXT__AVATAR_URL="https://avatars2.githubusercontent.com/u/1889831"
lhci upload --config=./lighthouserc.js --token=xxxxxx
シェルスクリプトを実行すると 5 個のデータがアップロードされていることがわかります。これは先程 numberOfRuns で指定した値分生成されたデータが全て登録されているということです。
$ bash -x upload.sh
...
Saving CI project kohsweb (e498177b-0226-4de2-afd7-f3bac71afce4)
Saving CI build (db6f110e-e970-4559-b106-5c52fbdcc445)
Saved LHR to http://localhost:3000 (cbd52b66-1725-4383-8532-4d4416392616)
Saved LHR to http://localhost:3000 (e2667737-53d7-4310-8b76-c9d95ca8192f)
Saved LHR to http://localhost:3000 (eea8c09a-a675-44c7-9263-f53bc625e4f3)
Saved LHR to http://localhost:3000 (d24c99d0-ee6e-4e6a-93b5-84c8a2efea91)
Saved LHR to http://localhost:3000 (39d3361d-0aad-4427-820c-463de43ebbea)
Done saving build results to Lighthouse CI
View build diff at http://localhost:3000/app/projects/kohsweb/compare/db6f110e-e970-4559-b106-5c52fbdcc445
No GitHub token set, skipping GitHub status check.
実際に登録されたデータは次のスクリーンショットのように時系列のグラフで表示されます。(これはデータ量が少ないので見栄えが悪いですが……)
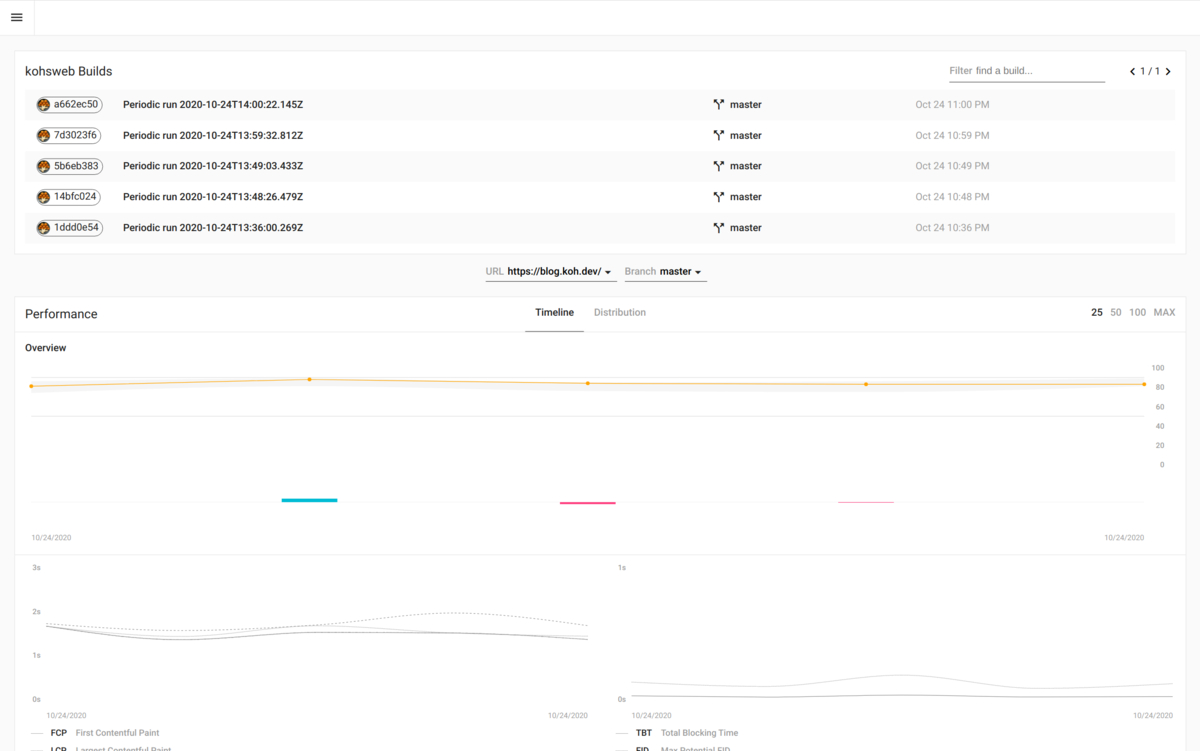
{{project name}} Builds の列がそれぞれ個別の結果のリンクになっています。
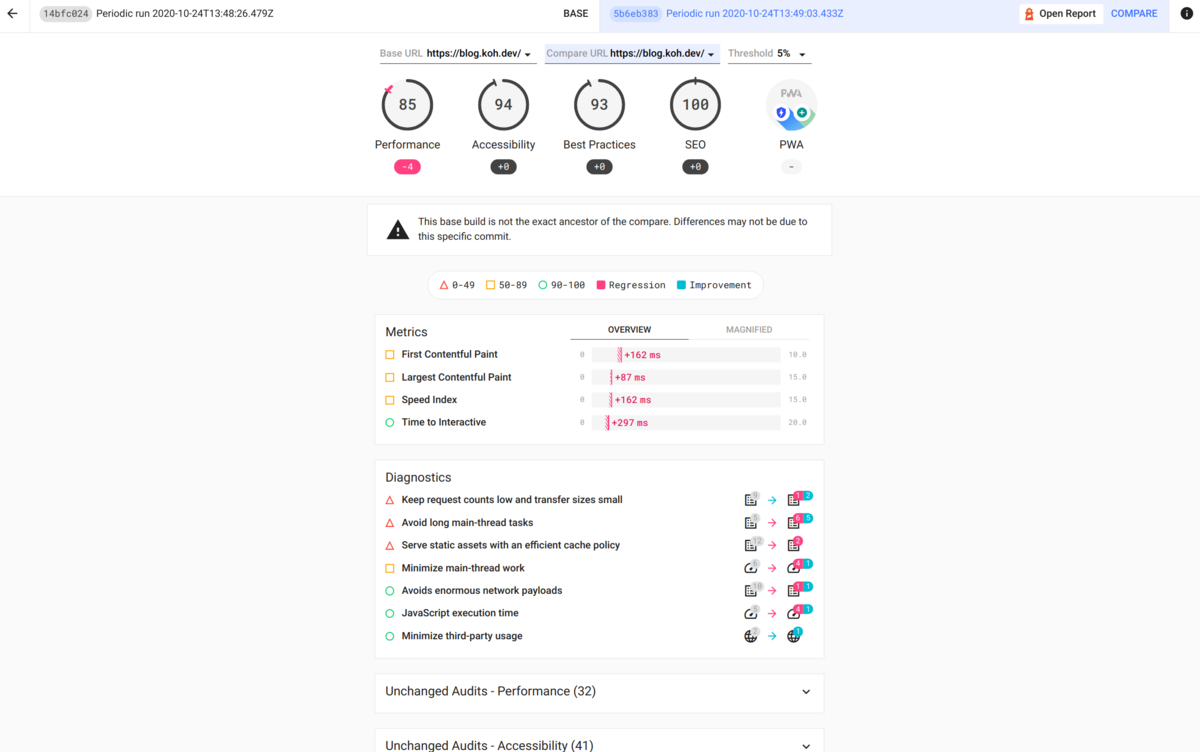
個別ページでは他のコミットハッシュからどれだけスコアの変動があったかを詳しく見ることができます。
また、右上にある COMPARE を hover すると Open Report というリンクが出てきます。これをクリックすると、そのコミットのスコア(いつも見慣れている Lighthouse の画面)を見ることもできます。(自分はこの機能をよく使います)
Lighthouse CI の運用 Tipslink
今までの内容で Lighthouse CI の環境を構築する具体的な方法と、データの登録方法について解説しました。 最後に実運用するにあたってわかった自分が気をつけている Tips について記載します。
lighthouserc.jslink
色々とやるうちに自分は次のような設定ファイルに落ち着きました。
const puppeteer = require('puppeteer')
module.exports = {
ci: {
collect: {
chromePath: puppeteer.executablePath(),
maxWaitForLoad: 180000
},
upload: {
target: 'lhci',
serverBaseUrl: 'http://localhost:3000',
ignoreDuplicateBuildFailure: true
}
}
}
解説時と違い numberOfRuns はデフォルト値のままです。増やしてもそんなに問題はないのですが、これは運用コストの問題です。
upload の箇所でも説明したのですが、5 回実行すると 5 個のデータが生成され登録されます。(実際は紐づく Table 数でもうちょっとレコード数は増えます)
これが結構馬鹿にならないデータ量になるのでデフォルトの値に戻しました。
また、実際に画面に表示されているのは、同じ buildId の中の representative フラグが 1 となっているもののみです。 他のデータは表示はされないのでゴミデータに近いものになるので、最小限にしたいと思っています。
mysql> select id,buildId,representative from runs limit 10;
+--------------------------------------+--------------------------------------+----------------+
| id | buildId | representative |
+--------------------------------------+--------------------------------------+----------------+
| 39d3361d-0aad-4427-820c-463de43ebbea | db6f110e-e970-4559-b106-5c52fbdcc445 | 0 |
| 4d7f18ec-1b35-4655-a846-35fbdd6706a7 | 480f155c-64ba-4c14-a8ee-275a88772dfc | 1 |
| 551f4b89-82aa-434f-bab4-db9d93772517 | 7e50d809-03e3-4588-b2a2-16924c55c0cd | 0 |
| 68c429ff-b1de-491f-8d16-b4fb0394c982 | 3c4813ee-1d23-4b52-8c16-f240366dec4e | 0 |
| 8f3f9293-cdec-4a03-9d88-521d8488c346 | 480f155c-64ba-4c14-a8ee-275a88772dfc | 0 |
| 9fd30cef-77b0-4dfa-b4fd-58a3a729faed | aea732c5-11e8-4755-8a8a-48cd9d869d17 | 1 |
| b72cad60-6b8c-4e6f-885c-b8292d6658ee | 3c4813ee-1d23-4b52-8c16-f240366dec4e | 0 |
| bc6da55f-22ec-4fda-975e-d29c5194baa6 | 480f155c-64ba-4c14-a8ee-275a88772dfc | 0 |
| cbd52b66-1725-4383-8532-4d4416392616 | db6f110e-e970-4559-b106-5c52fbdcc445 | 0 |
| cecc001d-661f-4159-a0a4-f4c9f9f09104 | 3c4813ee-1d23-4b52-8c16-f240366dec4e | 1 |
+--------------------------------------+--------------------------------------+----------------+
upload の設定項目にある ignoreDuplicateBuildFailure は入れなくても問題ないのですが、検証時に同じ HASH でアップロードしようとするとエラーになったりするので、検証時の挙動を楽にするために入れています。
定期的な実行link
これは cron による実行で問題ありません。次のようなコードを cron などで定期実行する事で Lighthouse のスコアを定期的に取得しています。
ここでの Tips は --addictive オプションと mobile を測定する時に ?mobile というクエリパラメータを付与している点です。
lhci collect --url=https://blog.koh.dev --settings.emulatedFormFactor=desktop --settings.throttling.cpuSlowdownMultiplier=1 --settings.throttling.throughputKbps=10240 --settings.throttling.rttMs=40 --config=/path/to/lighthouserc.js
lhci collect --url=https://blog.koh.dev?mobile --settings.emulatedFormFactor=mobile --settings.throttling.cpuSlowdownMultiplier=4 --settings.throttling.throughputKbps=1638.4 --settings.throttling.rttMs=150 --config=/path/to/lighthouserc.js --additive
export TZ="Asia/Tokeyo"
export LHCI_BUILD_CONTEXT__CURRENT_HASH=$(node -e "console.log(crypto.createHash('md5').update(Date.now().toString()).digest('hex'))")
export LHCI_BUILD_CONTEXT__COMMIT_TIME=$(node -e "console.log(new Date().toISOString())")
export LHCI_BUILD_CONTEXT__CURRENT_BRANCH=master
export LHCI_BUILD_CONTEXT__COMMIT_MESSAGE="Periodic run $(node -e "console.log(new Date().toISOString())")"
export LHCI_BUILD_CONTEXT__AUTHOR="kohta ito <koh110@example.com>"
export LHCI_BUILD_CONTEXT__AVATAR_URL="https://avatars2.githubusercontent.com/u/1889831"
lhci upload --config=./lighthouserc.js --token=xxxxxx
--addictive は collect コマンドを複数回実行する場合に必要になるオプションです。
collect コマンドは実行するたびに .lighthouse/ ディレクトリをクリアします。これは定期実行するにあたってはありがたい機能なのですが、複数の URL をパラメータを変えて計測する場合にはちょっと困ります。
なので上記の例では --addictive で mobile の計測を行う場合に、上書きして消してしまう事を防いでいます。
?mobile は URL をユニークにするためのパラメータです。文字列はなんでもかまいません。
Lighthouse CI は URL 単位でデータを扱うため、同じ画面の Desktop/Mobile の両方を計測しようとすると困ります。なので何かしらのクエリパラメータを与えることで別 URL として管理するようにしています。
また、mobile という文字列が入っていることで、その結果がどちらの UserAgent で計測したのかの視認性をよくするためにも利用しています。
MySQL 容量問題link
Lighthouse CI はよくできたツールで、実運用にあたってあまり困る部分がありません。唯一困るのは割と富豪的なリソースの使い方をするところです。
テーブル数は少ないのですが、このうち実行結果を保持する runs が非常に大きな容量を食っていきます。自分が実際に運用している計測環境では 7GB/月の速度でデータ量が増えています。
mysql> show tables;
+----------------------+
| Tables_in_lighthouse |
+----------------------+
| SequelizeMeta |
| builds |
| projects |
| runs |
| statistics |
+----------------------+
5 rows in set (0.00 sec)
レコードの中身を覗いてみるとわかるのですが、計測結果の json が文字列で保存されています。さらに結果に時系列のスクリーンショットデータが base64 エンコードで保存されているため、結構な容量を持っていかれます。
今のところの自分は次の対処をしています。
- 表示に使わないデータを定期的に削除する
- 古いデータを定期的に削除する
uplaod の箇所でも少し触れましたが、表示するデータは representative が 1 となっているデータのみです。なので representative = 0 となっているデータは今の所必要ありません。これを定期的に削除します。
mysql> SELECT COUNT(*) FROM runs WHERE representative = 0;
mysql> DELETE FROM runs WHERE representative = 0;
もうひとつは Lighthouse CI Server の設定に deleteOldBuildsCron を設定を追加して、一定期間以上のデータを削除することです。
この設定を追加することで、指定した期間(30 日以上等)のデータを削除する設定です。
Ref: deleteOldBuildsCron
deleteOldBuildsCron?: {
schedule: string;
maxAgeInDays: number;
}
自分が実運用上データ容量で困っていたので issue で相談したところ、こういう機能はどうかと返答をもらったので PR を送ったところ取り入れてもらえました。
まとめlink
Lighthouse CI についてコミットベースではなく定期実行でスコアを計測する方法と運用上の Tips をまとめました。
Web のパフォーマンスアップをするためにはともあれまず計測をして、現在地点を知らないといけません。Ligthouse CI で自分たちのサイトのパフォーマンスを知ってスコアの改善につなげていきましょう!